
Research Paper Review: Clothing Parsing by Image Segmentation
27 Jun 2017 | Computer Vision Research PaperToday at work, I was doing some research for my project when someone on the team shared this paper with me and asked me to read and understand it. It’s so far above my current understanding and skillset that I decided to write a blog post about it to help me understand what exactly I was learning.
Problem statement:
How to jointly segment the clothing images into regions of clothes and simultaneously transfer semantic tags at image level to these regions. There are several challenges in this problem:
- There are an infinite variation of poses
- There are a wide variety of clothing categories
- Clothes and garments have a huge variety of styles and textures as compared versus other common objects.
Abstract :
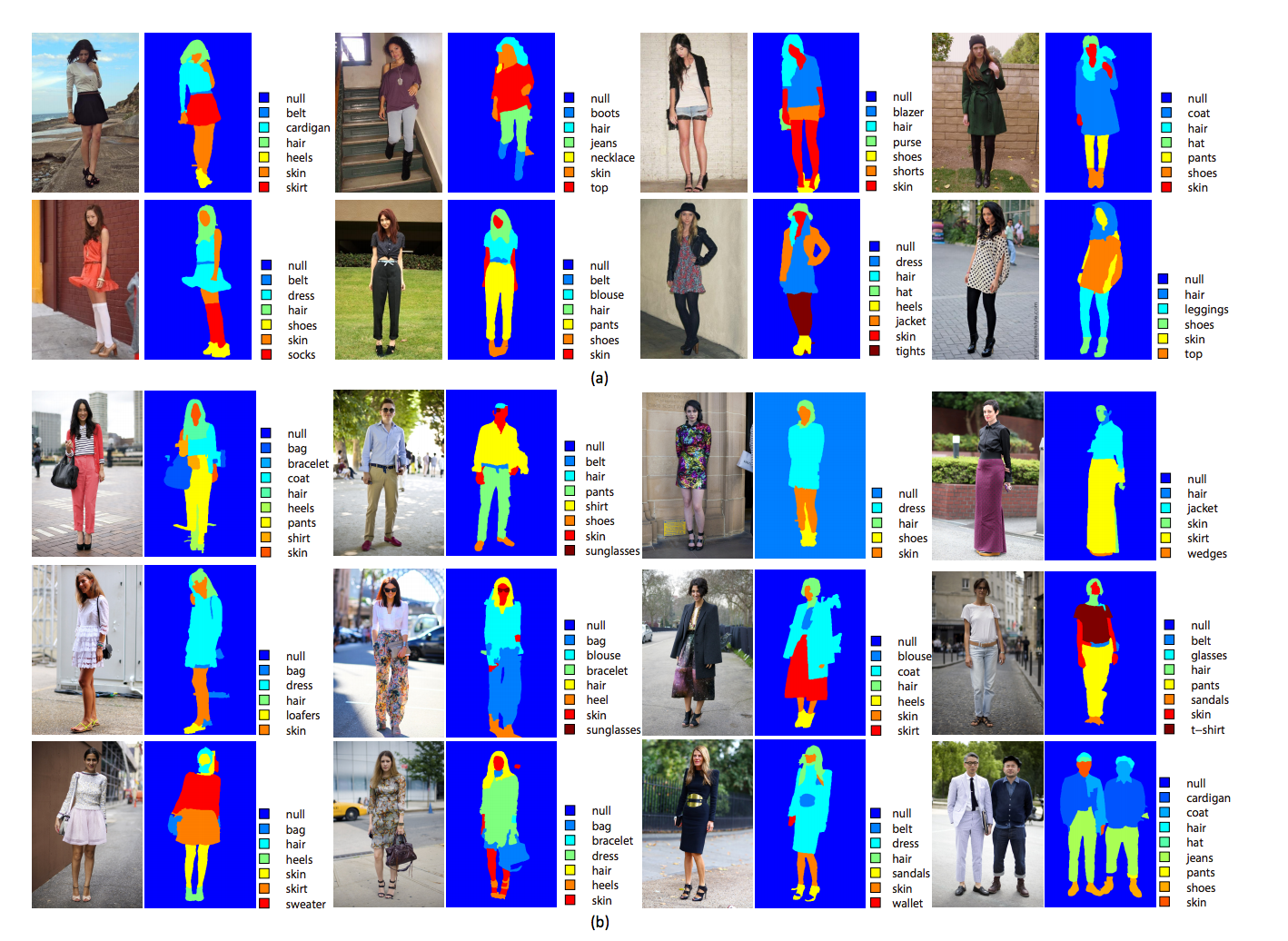
This paper wants to create a system which takes in an image of a person (dressed complexly and against busy city backgrounds, as street style is wont to do) and outputs an image that identifies each item of clothing and labels what it is. Its a 2 step process; The first phase uses an exemplar-SVM (E-SVM) to extract regions on images and refines them.
The second step constructs a multi-image graphical model by taking the segmented regions as vertices, and, based on contexts on the way the clothes are being worn (ie item location and mutual interactions), labels them using the Graph Cuts algorithm.
More In-depth Introduction:
Step 1: Iteratively refine regions grouped over all images by employing examplar-SVM (E-SVM)
First, extract superpixels and group them into regions. Most of these regions are cluttered and meaningless because of variations in clothing and humans. (A superpixel is an image patch which is better aligned with intensity edges than a rectangular patch)
Next, choose some coherent regions based on size and location.
Third, train a number of E-SVM ( essentially a math function that takes in a bunch of training inputs from training data sets, in this case a type of region from a dataset, and outputs a “yes this is the same thing” or a “no this isnt the same thing.”) classifiers for the selected regions using the HOG feature, i.e., one classifier for one region, and produce a set of region-based detectors, which are applied as top-down templates to localize similar regions over all images.
This allows for segmentations to be refined jointly because the trained E-SVM classifiers generate more coherent regions. The authors came up with this by realizing that clothing items of the same specific category often share shapes and structures.
Given all of this, however, it is very difficult to recognize then only by using supervised learning because of the large number of very specific categories and the large variations within classes.
Step 2: Phase 2 Co-labelling, Data-driven manner
First, they constructed a multi-image graphical model by taking the regions as vertices of graph.
Next, they link adjacent regions within each image as well as regions across different images, which shares similar appearance and latent semantic tags (tags coming from the dataset on the fashion website).
Thus they can borrow statisticalstrength from similar regions in different images and assign labels jointly. The optimization of co-labeling is solved by the efficient Graph Cuts algorithm that incorporates several constraints defined upon the clothing contexts.
Probabilistic Formulation
Uhhh yeah I’m not a genius; I took AP Statistics in high school, and Probability with Engineering Applications (Computer Engineering version) at the University of Illinois. I don’t understand this right now, but a high level understanding I gleaned is :
Use the probability that different superpixels are in a given region to identify different regions in an image. Group these to train E-SVMs. Then , look at the chance that similar shaped regions between different images have the same latent tags; if a lot of pictures with a roughly jacket like shape have the tag jacket, and a lot without this shape but all the others do, its probably a jacket.
PLEASE Take my the above as simply my understanding and not what it actually says because It was really confusing.
Detailed Explanation of Step 1: Unsupervised Image Co-Segmentation
The first phase iterates between 3 different steps; the optimization of R(set of regions in the image) while holding W(set of weights for the E-SVM) and C(segmentation propagation) constant, and vice versa.
i) Superpixel Grouping
The standard pipeline for superpixel grouping is a markov random field, or a set of variables that have a markov property (memoryless-ness in a stochiastic process) described by an undirected graph.
What needs to be specified is the number of regions. To automatically define this number, we replace the superpixel indicator with a set of binary variables defined on the edges between neighboring superpixels. if two superpixels whose edges meet at e belong to the same region, the indicator at e is 1. A super dumb-down of the math involved in this is “we want the most number of indicators at the most number of e’s to be 1”.
ii) Training E-SVM’s
Train an E-SVM classifier for each of the selected regions: Each selected region is considered as a positive example (exemplar), and a number of patches outside the selected region are cropped as negative examples.
In the implementation, they use HOG as the feature for each region (histogram of oriented gradients, or the idea that local object appearance and shape within an image can be described by the distribution of intensity gradients or edge directions).
The region selection indicator is determined by an automatic “noticable” detector. To be efficient, they only train the E-SVM’s for high confident foreground regions, ie those containing garment items.
iii) Segmentation Propagation
Search for possible propagations using the sliding window method. Since the E-SVM’s are trained independently, their responses may not be compatible; in this case they need to be calibrated by fitting a logistic distribution on the training set.
Detailed Explanation of Step 2: Unsupervised Image Co-Segmentation
I definitely cannot explain this much better then I did above (the math is difficult to take a stab at), but I can attempt to explain it with words.
The first step is to get information about each region we identified in the above step; its appearance, and its location with respect to other shapes.
The next step is to identify things that look similar and interact mutually. This works because some items, i.e jacket and pants will be next to each other, where as socks and a scarf will not.
The final step is to look across different images; regions in different images sharing similar appearance and locations are probably the same garment.

Experiments
After being trained on 2 different data sets, this model is about 90 percent accurate at matching pixels to the right garments, and 65 percent accurate at identifying garments right.